
With just a few days to go until WWDC 2025, Apple published a new AI study that could mark a turning point for the future of AI as we move closer to AGI.
Apple created tests that reveal reasoning AI models available to the public don’t actually reason. These models produce impressive results in math problems and other tasks because they’ve seen those types of tests during training. They’ve memorized the steps to solve problems or complete various tasks users might give to a chatbot.
But Apple’s own tests showed that these AI models can’t adapt to unfamiliar problems and figure out solutions. Worse, the AI tends to give up if it fails to solve a task. Even when Apple provided the algorithms in the prompts, the chatbots still couldn’t pass the tests.
Apple researchers didn’t use math problems to assess whether top AI models can reason. Instead, they turned to puzzles to test various models’ reasoning abilities.
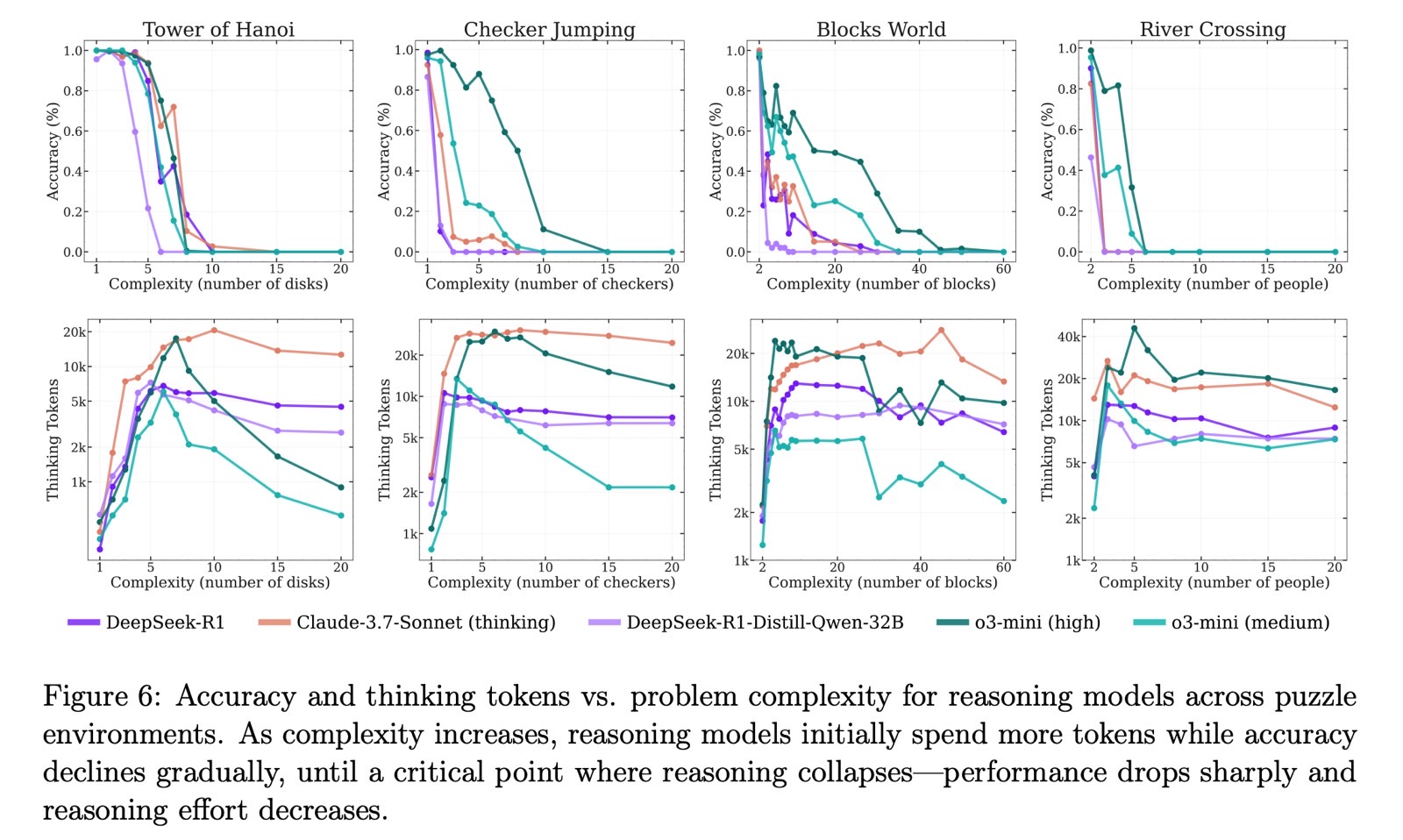
The tests included puzzles like Tower of Hanoi, Checker Jumping, River Crossing, and Blocks World. Apple evaluated both regular large language models (LLMs) and large reasoning models (LRMs) using these puzzles, adjusting the difficulty levels.
Apple tested LLMs like ChatGPT GPT-4, Claude 3.7 Sonnet, and DeepSeek V3. For LRMs, it tested ChatGPT o1, ChatGPT o3-mini, Gemini, Claude 3.7 Sonnet Thinking, and DeepSeek R1.
The scientists found that LLMs performed better than reasoning models when the difficulty was easy. LRMs did better at medium difficulty. Once the tasks reached the hard level, all models failed to complete them.
Apple observed that the AI models simply gave up on solving the puzzles at harder levels. Accuracy didn’t just decline gradually, it collapsed outright.
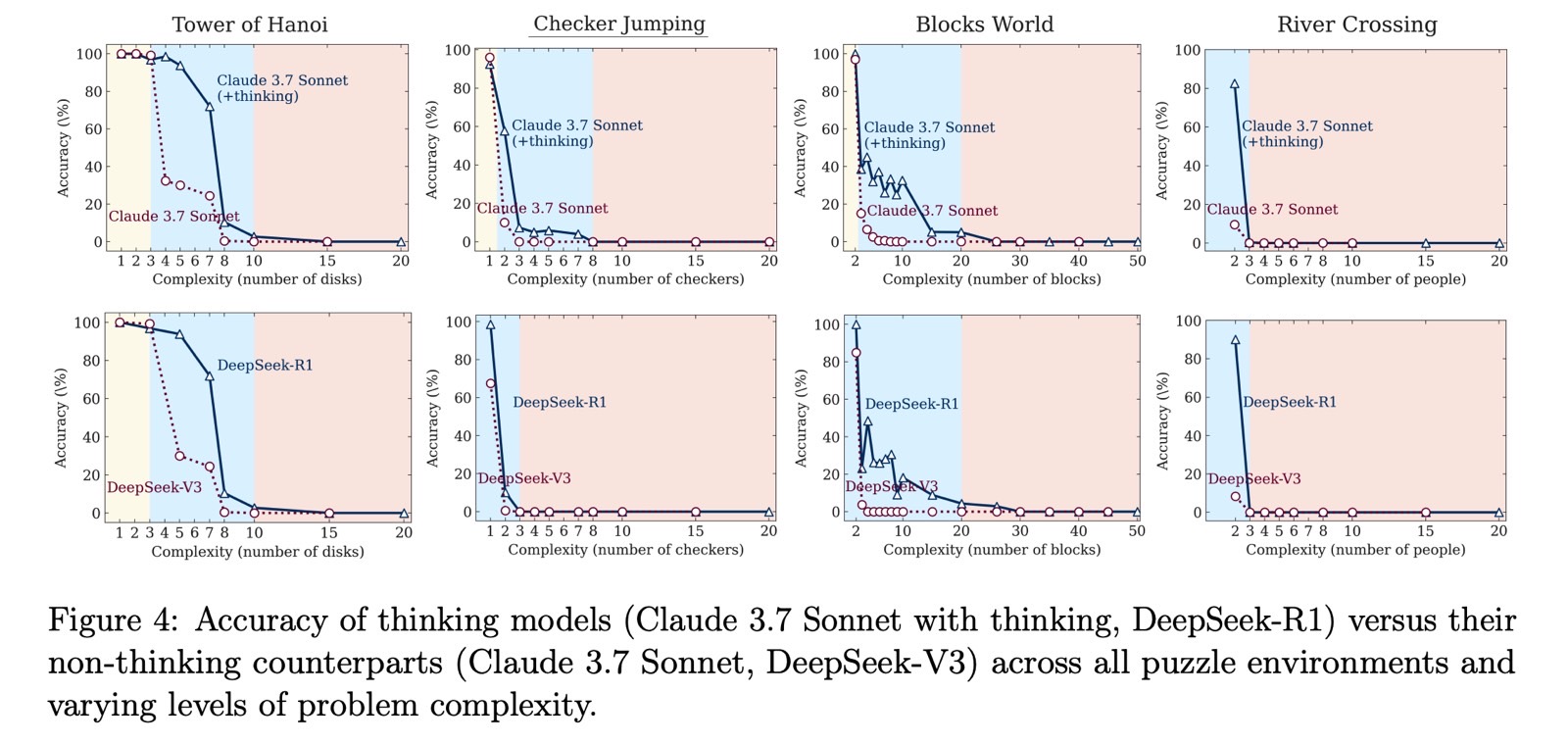
The study suggests that even the best reasoning AI models don’t actually reason when faced with unfamiliar puzzles. The idea of “reasoning” in this context is misleading since these models aren’t truly thinking.
The Apple researchers added that experiments like theirs could lead to further research aimed at developing better reasoning AI models down the road.
Then again, many of us already suspected that reasoning AI models don’t actually think. AGI, or artificial general intelligence, would be the kind of AI that can figure things out on its own when facing new challenges.
I’ll also point out the obvious “grapes are sour” angle here. Apple’s study might be a breakthrough, sure. But it comes at a time when Apple Intelligence isn’t really competitive with ChatGPT, Gemini, and other mainstream AI models. Forget reasoning—Siri can’t even tell you what month it is. I’d choose ChatGPT o3 over Siri any day.
The timing of the study’s release is also questionable. Apple is about to host its annual WWDC 2025, and AI won’t be the main focus. Apple still trails OpenAI, Google, and other AI companies that have released commercial reasoning models. That’s not necessarily a bad thing, especially given that Apple continues to publish studies that showcase its own research and ideas in the field.
Still, Apple is basically saying that reasoning AI models aren’t as capable as people might believe, just days before an event where it won’t have any major AI advancements to announce. That’s fine too. I say this as a longtime iPhone user who still thinks Apple Intelligence has potential to catch up.
The study’s findings are important, and I’m sure others will try to verify or challenge them. Some might even use these insights to improve their own reasoning models. Still, it does feel odd to see Apple downplay reasoning AI models right before WWDC.
I’ll also say this: as a ChatGPT o3 user, I’m not giving up on reasoning models even if they can’t truly think. o3 is my current go-to AI, and I like its responses more than the other ChatGPT options. It makes mistakes and hallucinates, but its “reasoning” still feels stronger than what basic LLMs can do.




